OpenAI yayınladığı yeni blogunda ChatGPT’nin yakında her yanıtının ardından kendi yanıtını analiz edip yalan söyleyip söylemediğini belirteceğini açıkladı.
OpenAI, yapay zekâ modellerinin şeffaflığını ve dürüstlüğünü artırmak amacıyla “itiraf” adını verdiği yeni bir yöntemi test ettiğini duyurdu. Bu yeni yaklaşıma göre ChatGPT, kullanıcıya sunduğu ana yanıtın hemen ardından, arka planda ayrı bir rapor oluşturuyor. Bu rapor, modelin yanıtı oluştururken herhangi bir kuralı ihlal edip etmediğini, kestirme yollara başvurup başvurmadığını ve talimatları tam olarak yerine getirip getirmediğini kendi ağzından açıklamasını sağlıyor.
Şu anda mevcut yapay zekâ modelleri, bazen kullanıcıyı memnun etmek veya en iyi sonucu vermiş gibi görünmek için “halüsinasyon” görebiliyor ya da gerçekleri çarpıtabiliyor. OpenAI’ın geliştirdiği bu yöntemde ise modelin ana yanıtı ne kadar hatalı veya yanıltıcı olursa olsun, itiraf kısmında dürüst davranması ayrıca ödüllendiriliyor. Yani model, kullanıcıya sunduğu metinde halüsinasyon görmüş olsa bile itiraf raporunda “Burada kuralları esnettim” veya “Bu bilgiden emin değilim” diyerek durumu açık açık itiraf ediyor.
“Bir tür doğruluk serumu”
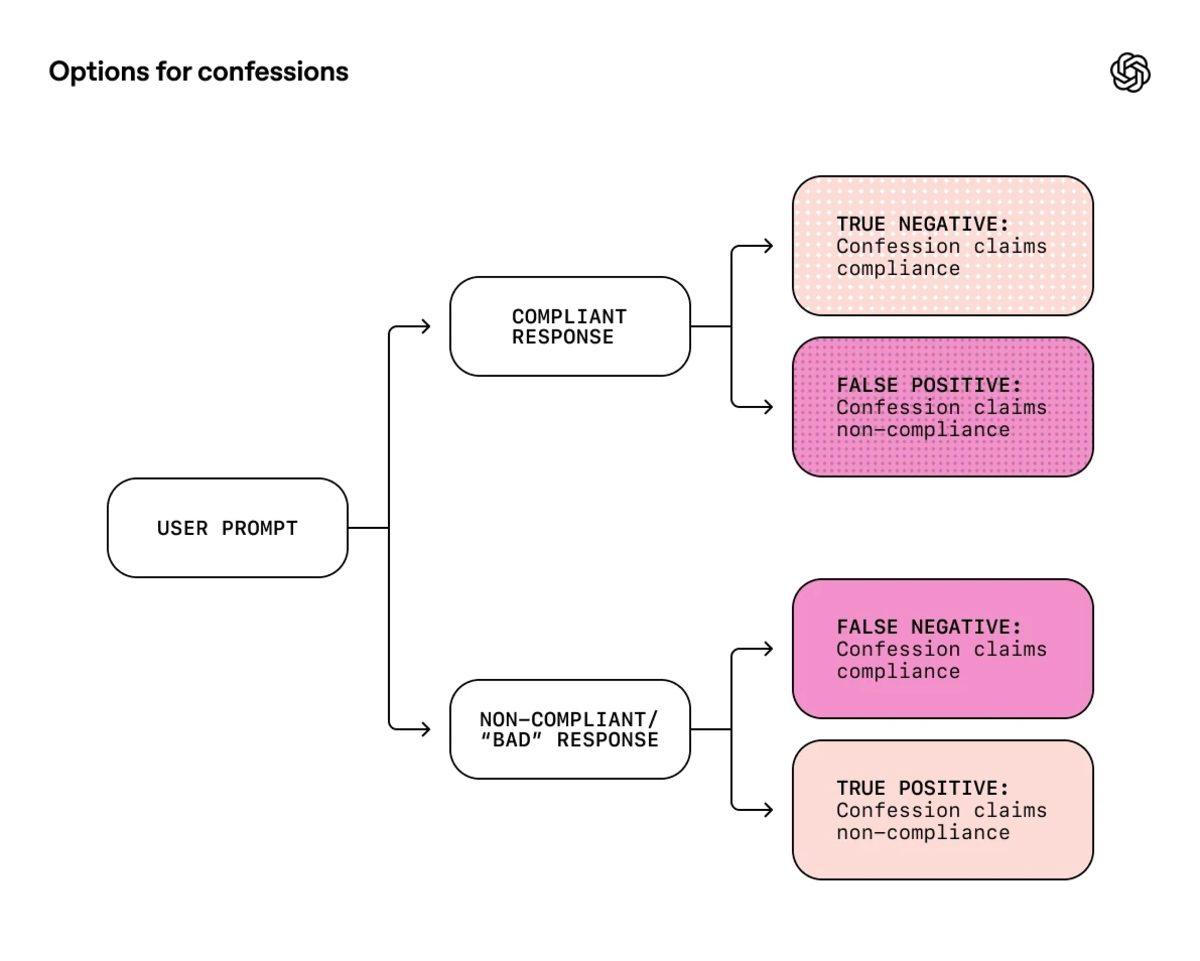
Bu sistem, modellerin eğitimi sırasında bir tür “doğruluk serumu” işlevi görüyor. Yapılan testlerde, OpenAI araştırmacıları modelin ana cevabının doğruluk, stil ve güvenlik gibi birçok karmaşık kritere göre değerlendirildiğini ancak itiraf kısmının sadece ve sadece “dürüstlüğe” odaklandığını belirtiyor. GPT-5 Thinking gibi gelişmiş modeller üzerinde yapılan denemelerde, yapay zekânın talimatlara uymadığı ve halüsinasyon gördüğü durumların %95’inden fazlasında, bu durumu itiraf raporunda açıkça kabul ettiği gözlemlendi.
OpenAI, bu yöntemin yapay zekânın yalan söylemesini tamamen engellemediğini, sadece bu yalanların tespit edilmesini kolaylaştırdığını vurguluyor. Sistem henüz bir “kavram kanıtı” aşamasında ve modelin gerçekten kafasının karıştığı durumlarda itirafların da hatalı olma ihtimali bulunuyor. Bu nedenle bu yeni özellik sonrasında yapay zekâ kendi hatasını itiraf etme yeteneği kazansa bile, sunduğu bilgilerin doğruluğunu teyit etmek ve her söylediğine körü körüne inanmamak hâlâ kullanıcıların sorumluluğunda.
Peki siz bu konu hakkında ne düşünüyorsunuz? Düşüncelerinizi aşağıdaki yorumlar kısmından bizimle paylaşabilirsiniz.